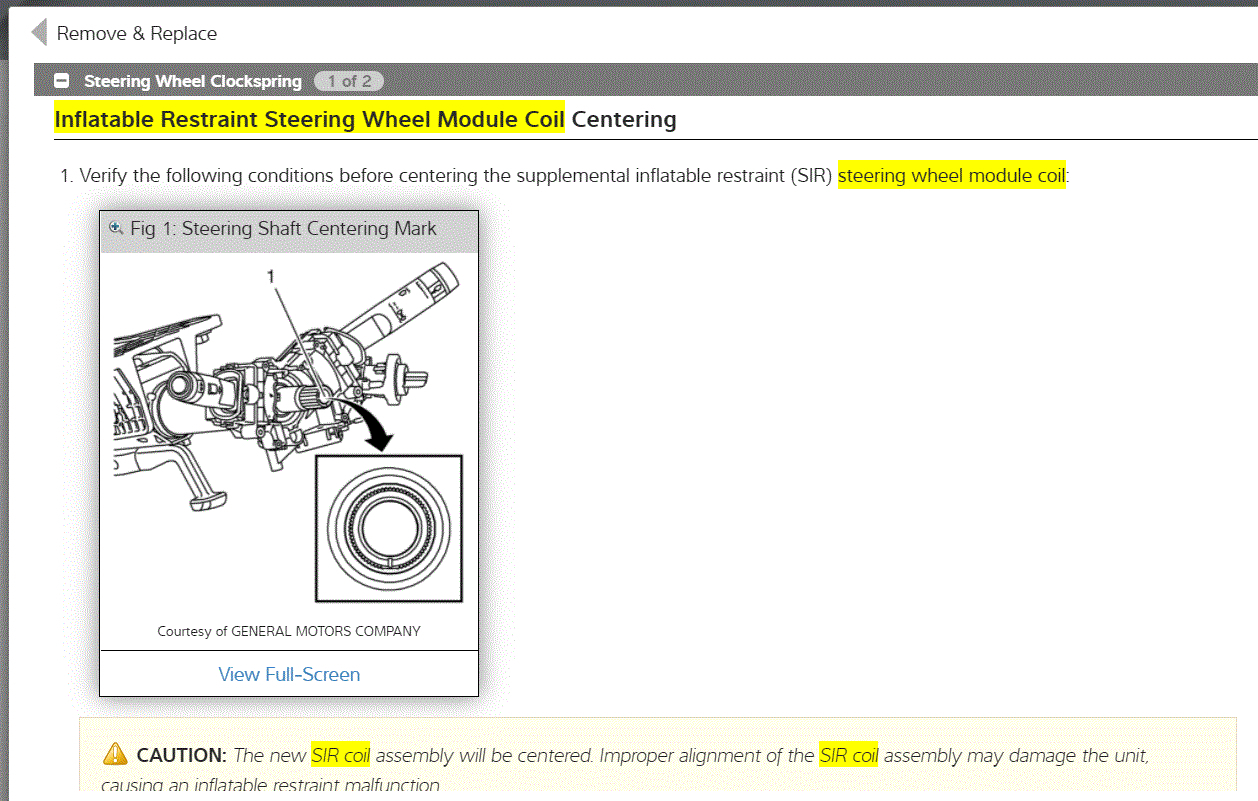
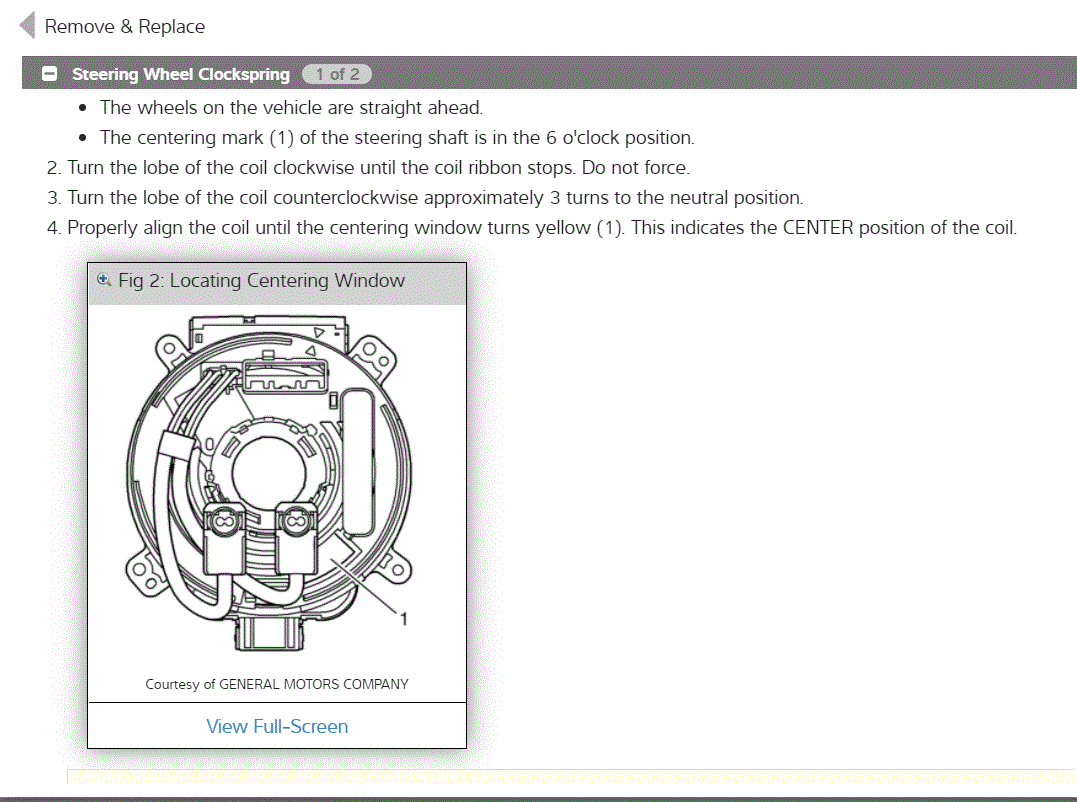
Hi,
As far as the removable steering wheel, I'm not sure what was done. However, the horn relay is under the hood fuse/relay box.
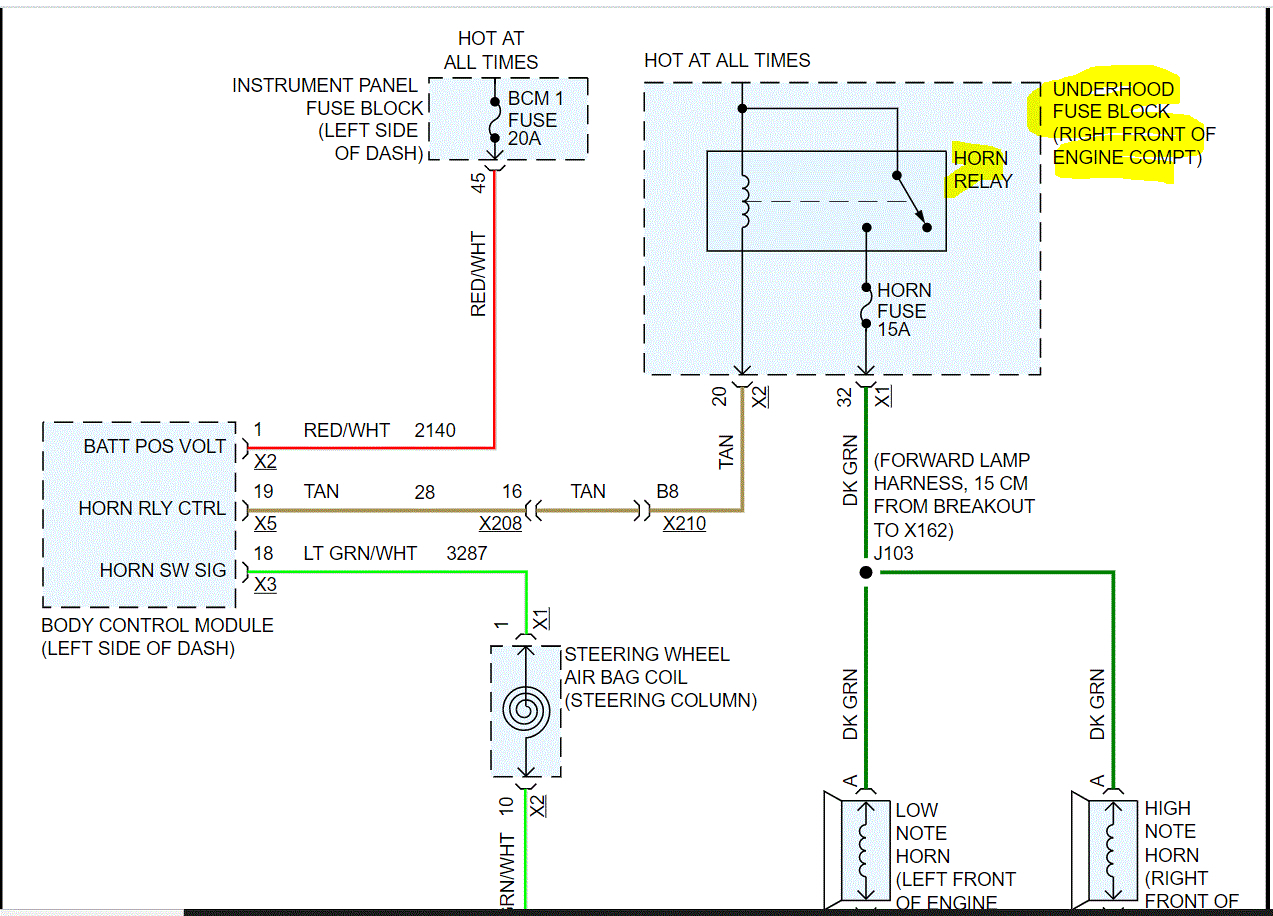
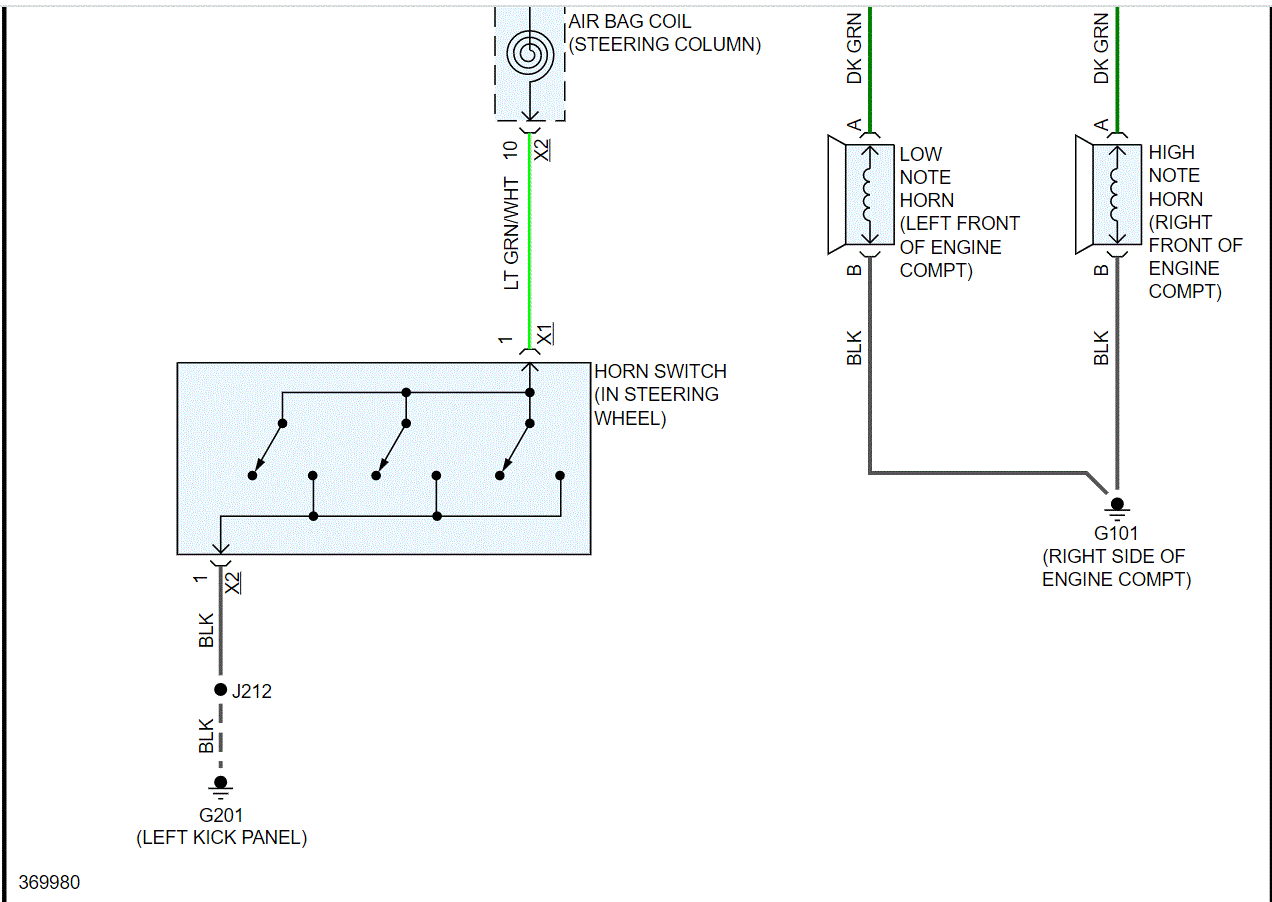
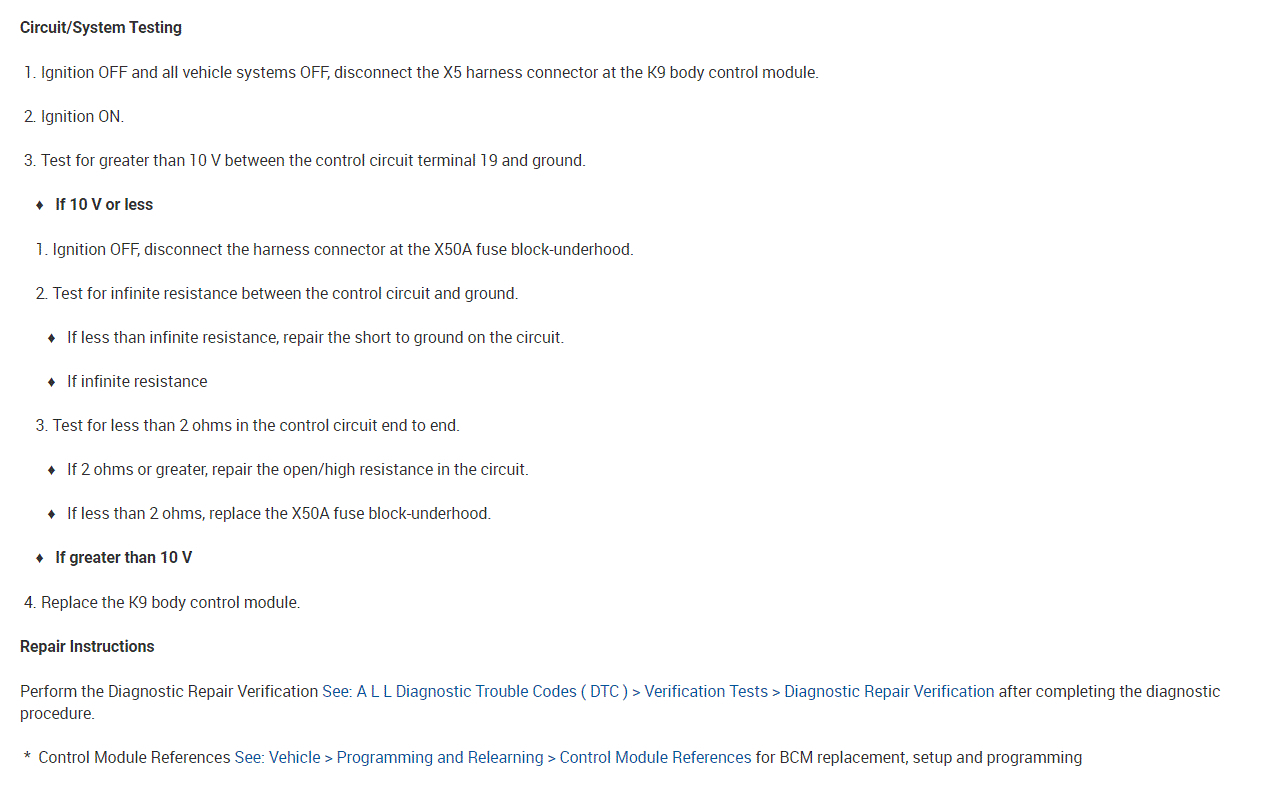
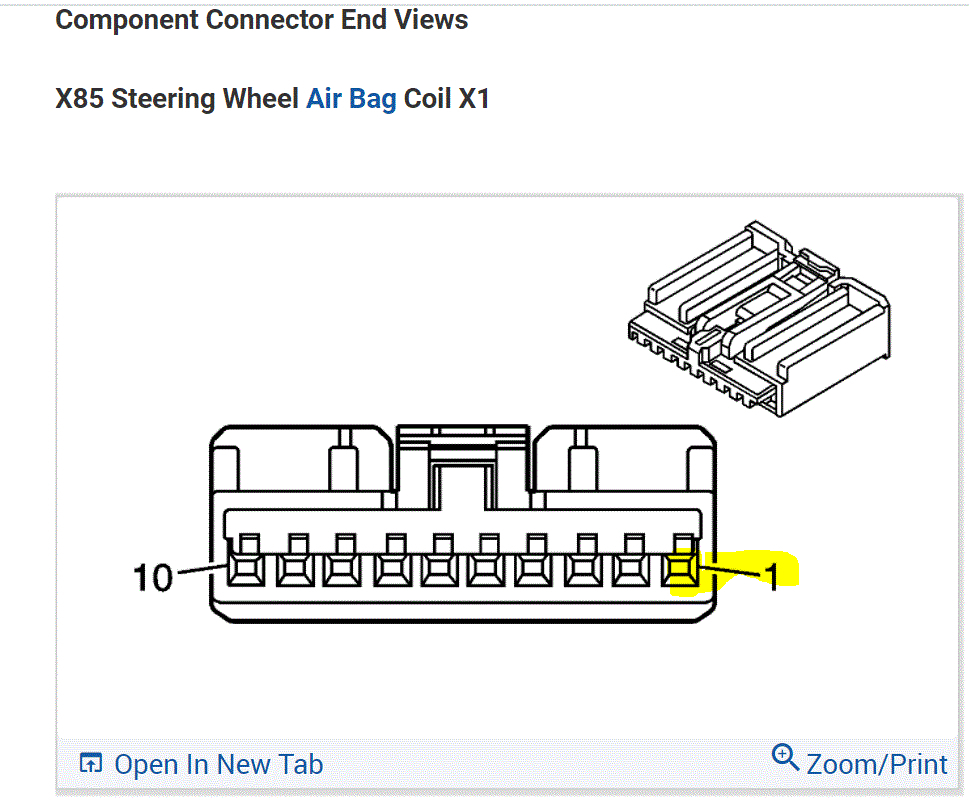
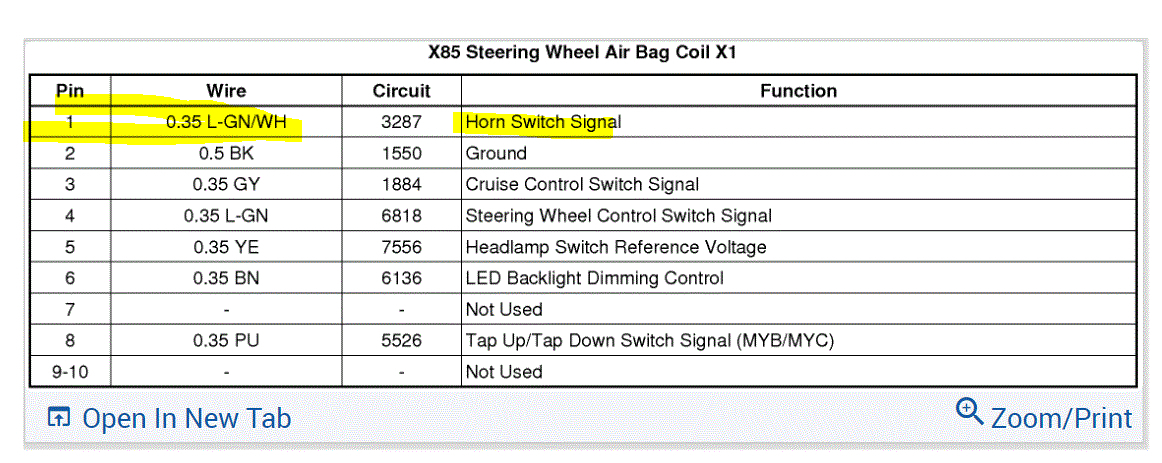
If you look below, I attached the wiring schematic for the horn circuit. I highlighted the relay. I had to cut the pic in half to make it readable, but I did overlap them so you can follow from one to the next.
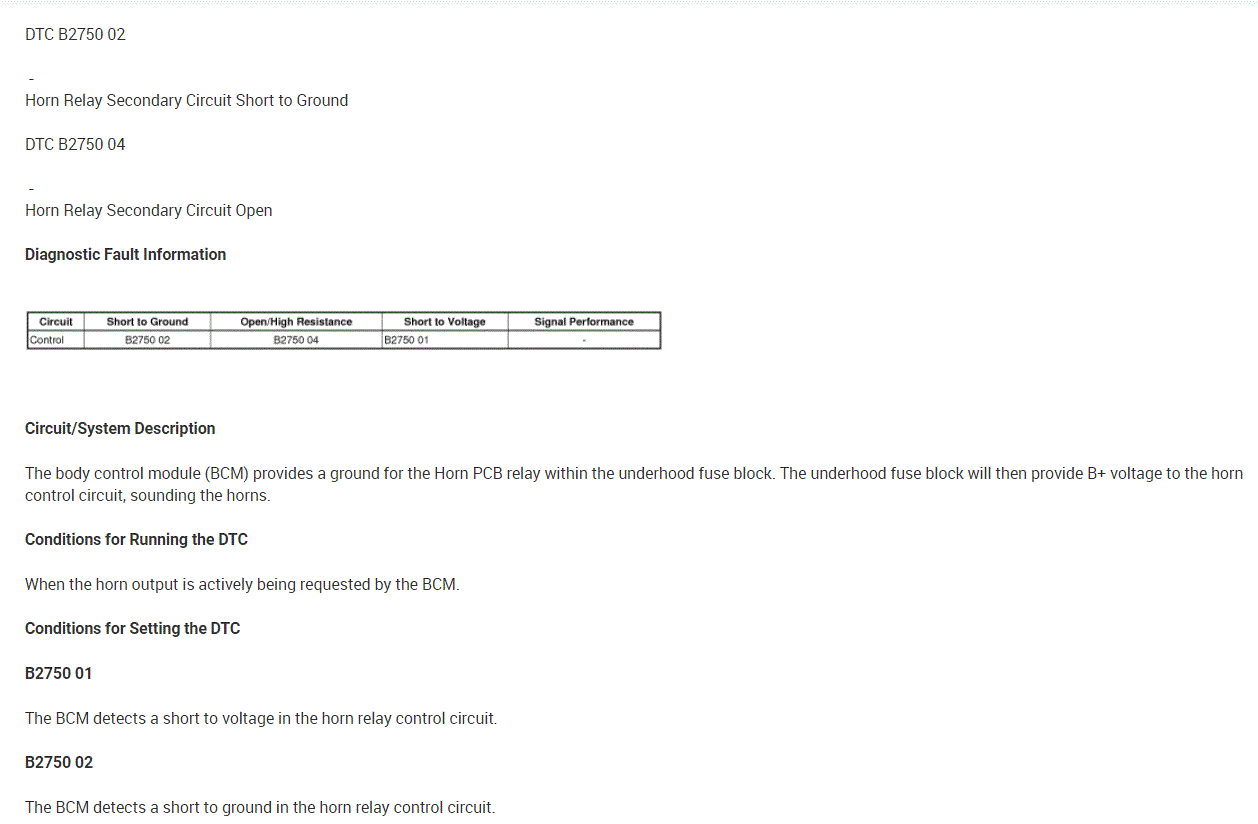
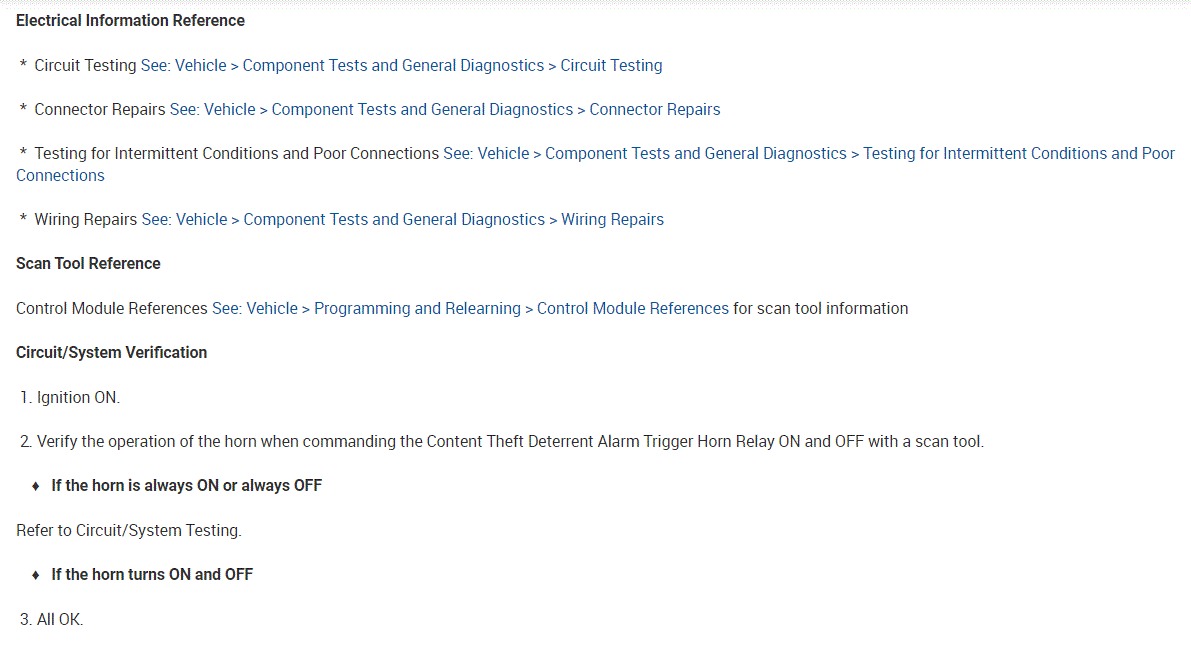
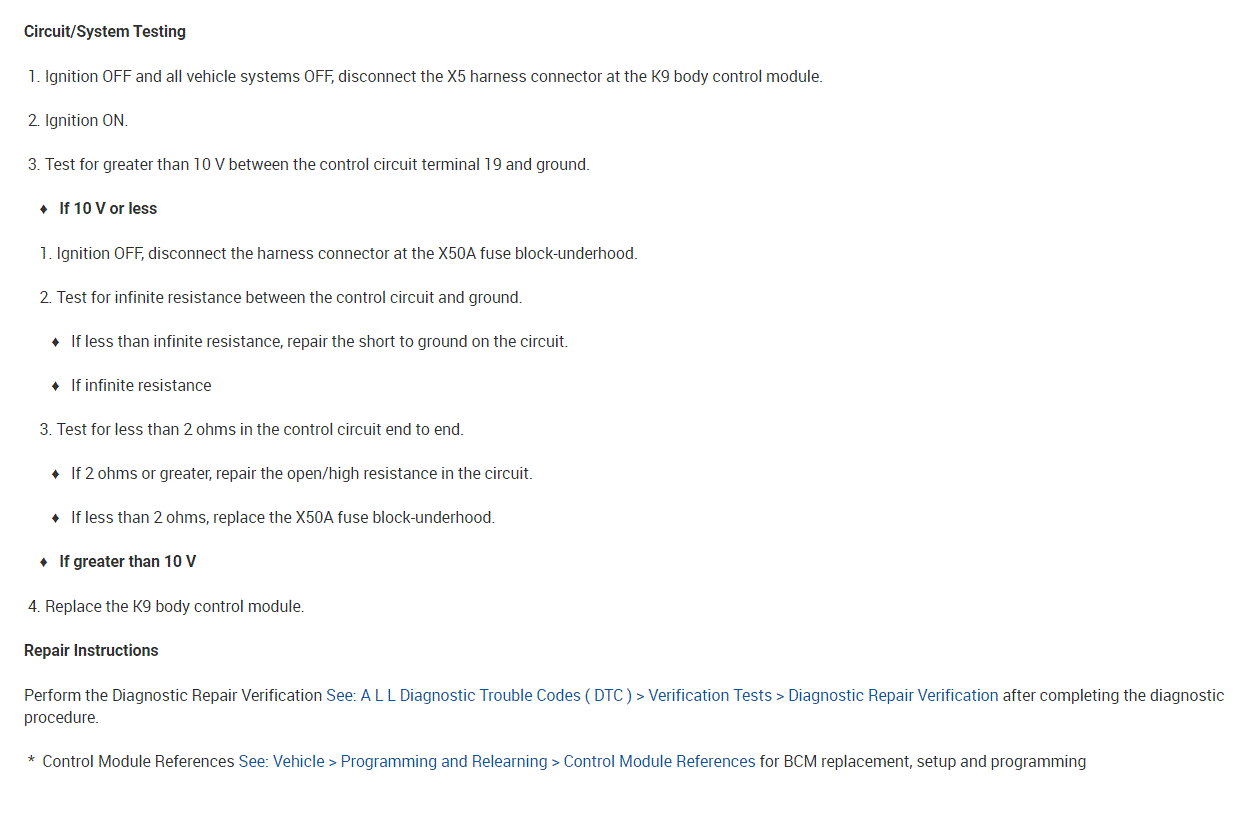
As far as the relay, here is how it works. The body control module, BCM, controls the horn operation. When the horn switch is pressed, it closes a switch pulling the horn signal circuit low. When the BCM detects the drop in voltage in the horn switch signal circuit, it energizes the printed circuit board, PCB, horn relay which provides B+ voltage to the horn control circuit, sounding the horn.
Now here is the bad news. If the relay is bad, it isn't serviceable. The relay box will need to be replaced. So, we need to be sure that is the issue.
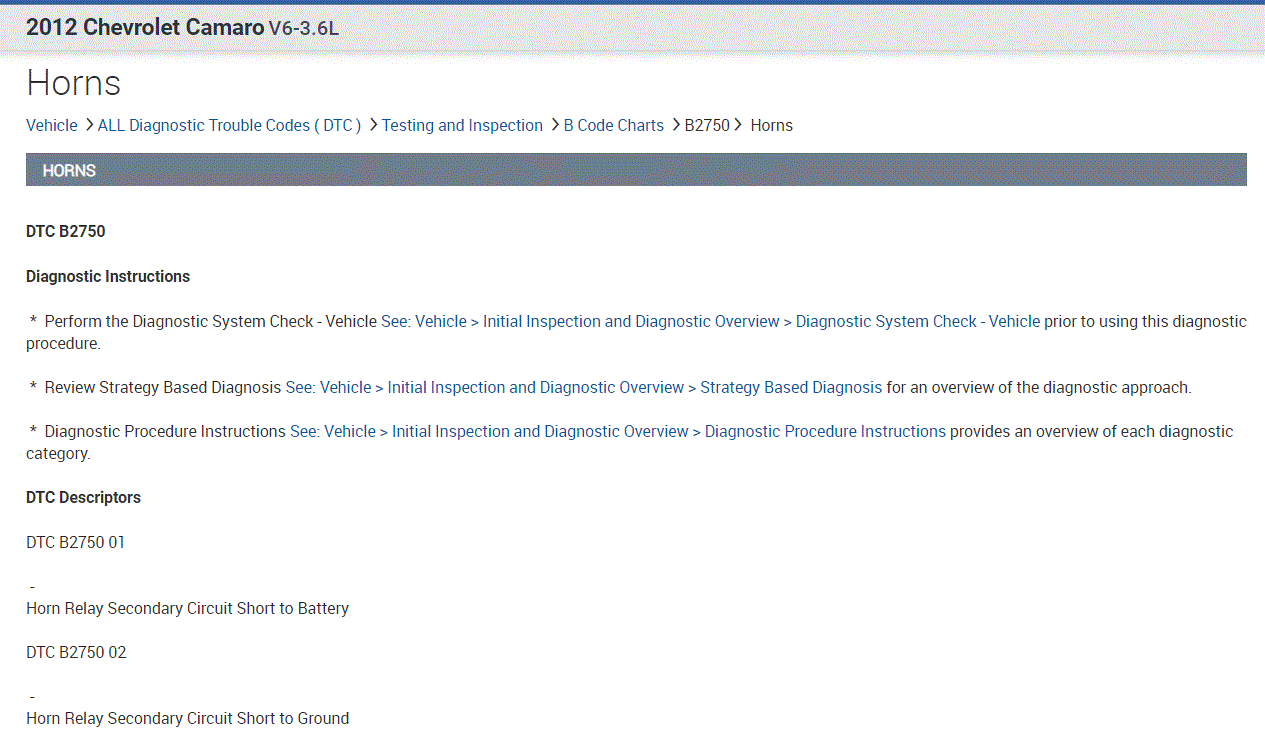
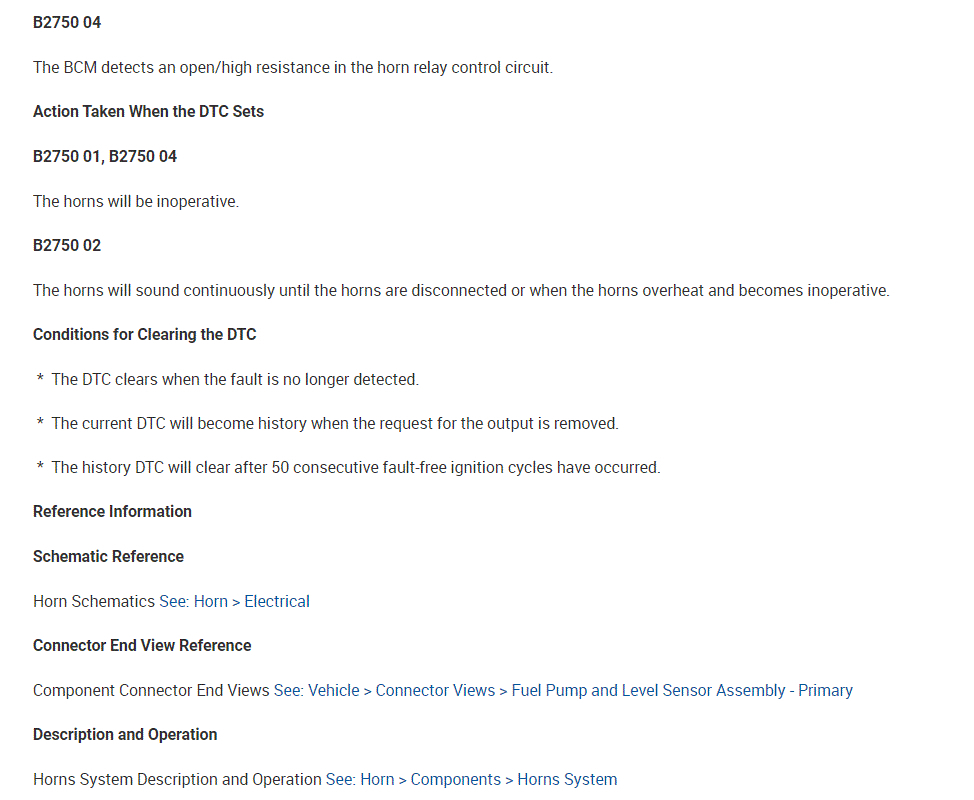
Here is what I recommend: First, scan the can bus system. CAN stands for controller area network. Basically, a few wires tie together all the modules/computers. By scanning the CAN, you will be able to identify where the problem is coming from. You should get a code. It will not be the typical "P" code, but rather a "B" code. Here is a quick video showing the CAN being scanned:
https://youtu.be/InIlnsjOVFA
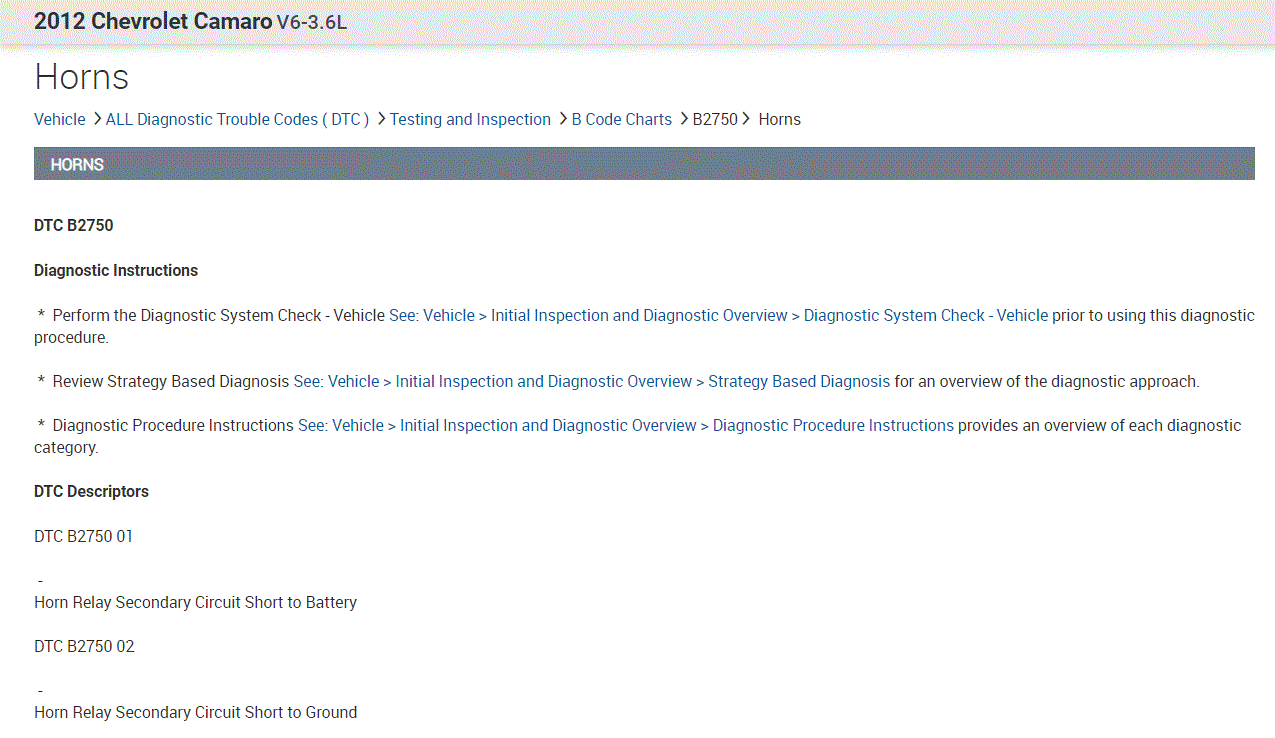
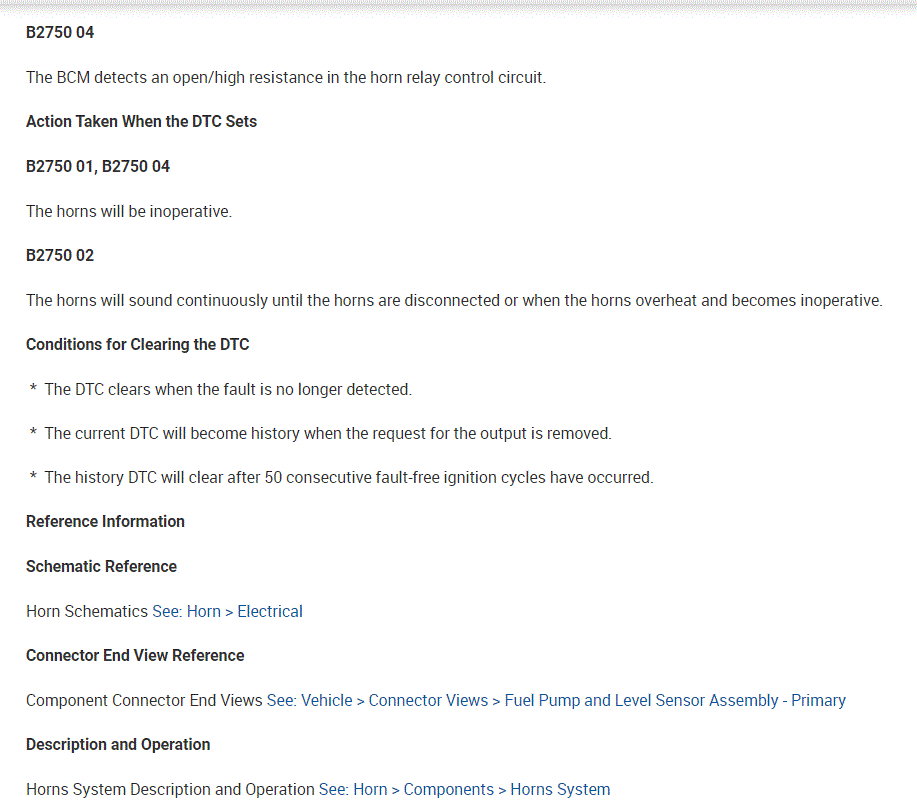
Once you get that, go through the diagnostics I provided below starting with the third pic.
Here is a link you may find helpful when testing:
https://www.2carpros.com/articles/how-to-check-wiring
Take care and let me know if this helps.
Joe
See pics below.
Images (Click to make bigger)
Tuesday, May 11th, 2021 AT 9:16 PM