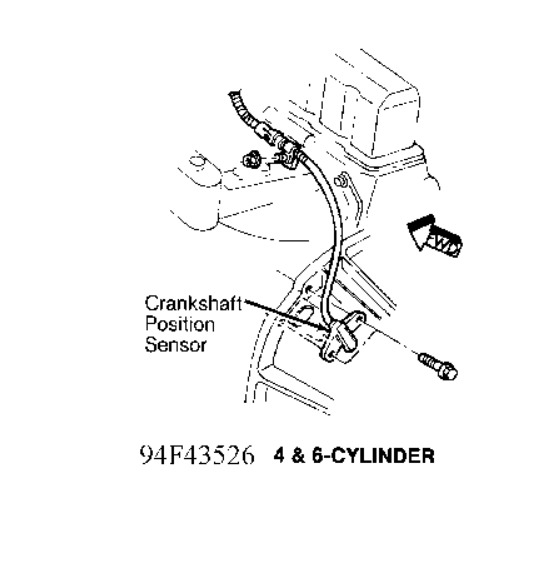
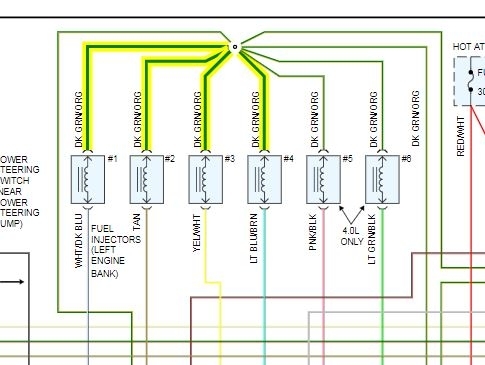
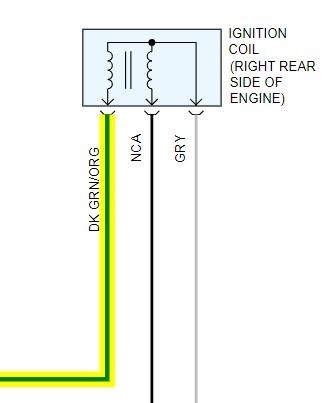
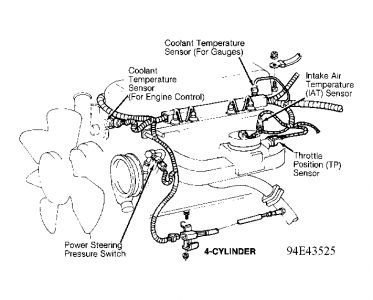
[quote:e0b34a2ed3="rejdepic"]Hi, my wrangler died on me driving for the 2nd time.
94 yj 2,5 l. 4 cyl man .
everything seems to work but would not restart. I had a ecm changed, run with it for a week and did the same thing again.
The mecano told me that the ecm would not open the injectors. fire is fine, fuel is fine.
Would this be an electrical problem?
Is a 2nd ecm fried ?
Or does both ecm still in working order?
Anyway of checking those
Summer is running out fast and I am Jeepless.
Thanks for helping
The mecano told me that the ecm would not open the injectors. fire is fine, fuel is fine.
Reggie[/quote:e0b34a2ed3]
Try disconnecting an injector connector and use a noid light while cranking it over is the lite flashing?
Sep 24, 2020 at 6:26 PM
(Merged)